VidTok团队 投稿狠狠射成人 量子位 | 公众号 QbitAI Sora、Genie等模子会都用到的Tokenizer,微软下手了—— 开源了一套万能的Video Tokenizer,名为VidTok。 Sora等视频生成模子责任中,都会运用Tokenizer将原始的高维视频数据(如图像和视频帧)调度为更为紧凑的视觉Token,再以视觉Token为想法磨练生成模子。 而最新的VidTok,在贯穿和碎裂、不同压缩率等多种设定下,各格式的均显耀优于SOTA模子。 以下是涵盖PSNR、SSIM、...

VidTok团队 投稿狠狠射成人
量子位 | 公众号 QbitAI
Sora、Genie等模子会都用到的Tokenizer,微软下手了——
开源了一套万能的Video Tokenizer,名为VidTok。
Sora等视频生成模子责任中,都会运用Tokenizer将原始的高维视频数据(如图像和视频帧)调度为更为紧凑的视觉Token,再以视觉Token为想法磨练生成模子。
而最新的VidTok,在贯穿和碎裂、不同压缩率等多种设定下,各格式的均显耀优于SOTA模子。

以下是涵盖PSNR、SSIM、FVD、LPIPS目的的性能比较雷达图,面积越大示意性能越好。
从图中不错看出关于碎裂Tokenizer,VidTok显耀优于英伟达Cosmos Tokenizer;关于贯穿Tokenizer,VidTok也比Open-Sora、CogVideoX有更高的性能。

这项参议由来自微软亚研院、上海交通大学、北京大学的参议东谈主员共同完成。

当今,VidTok代码不仅开源了,还守旧用户在自界说数据集上的微调,为参议者和设立者提供了一个高性能、易用的器具平台。
性能全面超过,适用各种场景连年来,视频生成以及基于此的全国模子依然成为东谈主工智能界限的热点参议标的,这两者的中枢在于对视频本色的高效建模。
视频中蕴含了丰富的视觉信息,不仅大略提供实在的视觉体验,更能行动具身场景中模子通晓全国的中间引子。
干系词,由于视频像素级示意信息高度冗余,怎么通过Tokenizer对视频数据进行高效压缩和示意成为关节课题。
当下许多责任如Sora,Genie等都和会过Tokenizer将原始的高维视频数据(如图像和视频帧)调度为更为紧凑的视觉Token,再以视觉Token为想法磨练生成模子。
不错说,视觉Token的示意才气关于最终的遵守至关病笃,甚而决定了模子才气的上限。
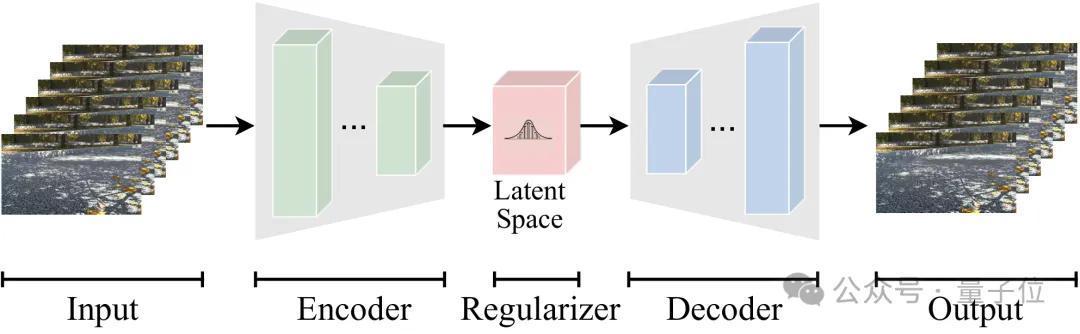
Tokenizer的主要作用是将高维的原始数据调度为隐空间中高效的压缩示意,使得信息的生成和措置不错在该隐空间中进行。上图展示了一个视频的Token化流程,通过调度为Token建模,大略灵验裁减模子磨练和推理时的探讨需求。
字据不同的使用需求,视频Tokenizer频繁有如下分类:
贯穿型和碎裂型。字据隐空间的数值散布,Tokenizer不错分为贯穿型和碎裂型,远隔适用于从贯穿散布中采样的模子(如扩散模子等)和从碎裂散布中采样的模子(如谈话模子等)。因果型和非因果型。因果结构使得模子只依赖历史帧来对刻下帧进行Tokenization,这与实在全国系统的因果性质保合手一致。非因果模子则不错同期字据历史帧和往时帧对刻下帧进行Tokenization,频繁具有更优的重建质料。不同的压缩率模子。Sora等繁多责任收受了如4x8x8的视频压缩率(时辰压缩4倍、空间压缩8倍),杀青更高的视频压缩率而保合手高质料的视频重建是当今的参议趋势。当今业界超过的视频模子多为闭源景况,而开源的视频Tokenizer大多受限于单一的模子设定或欠佳的重建质料,导致可用性较差。
由此,来自微软亚研院、上海交通大学和北京大学的参议东谈主员最近谨慎发布了开源视频Tokenizer——VidTok。
在测试中,VidTok性能全面超过,适用各种场景。
如下表所示,VidTok守旧各种化的隐空间且具有生动的压缩率,同期守旧因果和非因果模子,以得当不同的使用需求。
关于贯穿型Tokenizer,守旧不同的视频压缩率、不同的隐空间通谈数,同期守旧因果和非因果模子。关于碎裂型Tokenizer,守旧不同的视频压缩率、不同的码本大小,同期守旧因果和非因果模子。更多模子在合手续更新中。
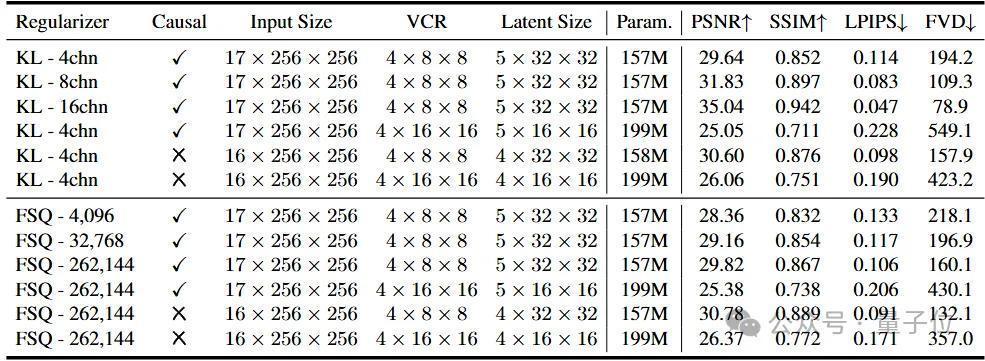
为了全面评估VidTok在各个设定下的重建性能,作家将VidTok与开首进的贯穿和碎裂视频Tokenizer远隔进行了对都设定下的比较。通盘模子均为4x8x8倍视频压缩率的因果模子,主要包含以下三种设定:
VidTok-FSQ:碎裂型,码本大小差异。基线身手包括MAGVIT-v2,OmniTokenizer,Cosmos-DV等。VidTok-KL-4chn:贯穿型,隐空间通谈数为4。基线身手包括CV-VAE,Open-Sora-v1.2,Open-Sora-Plan-v1.2等。VidTok-KL-16chn:贯穿型,隐空间通谈数为16。基线身手包括CogVideoX,Cosmos-CV等。定量实践限度标明,VidTok在上述三种设定下均达到了SOTA性能,在常见的视频质料评估目的PSNR、SSIM、FVD、LPIPS上具有全面的上风。
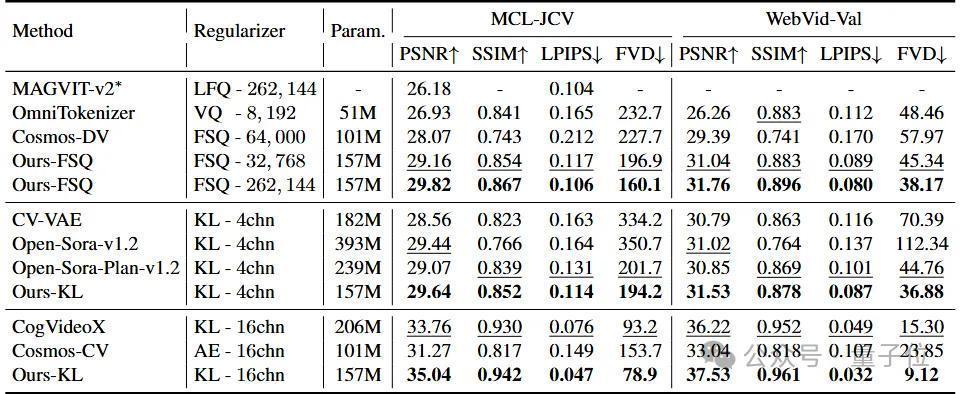
与现存的碎裂Tokenizer比拟,VidTok即使在使用更小的码本大小时(举例32,768),也展现出了更优的重建性能。
在贯穿Tokenizer的设定下,无论隐空间通谈数是4如故16,VidTok在通盘评估目的上比拟基线身手均取得了全面的提高。值得正经的是,这些提高是在莫得模子大小上风的情况下达成的。
除此以外,团队还进行了定性分析。
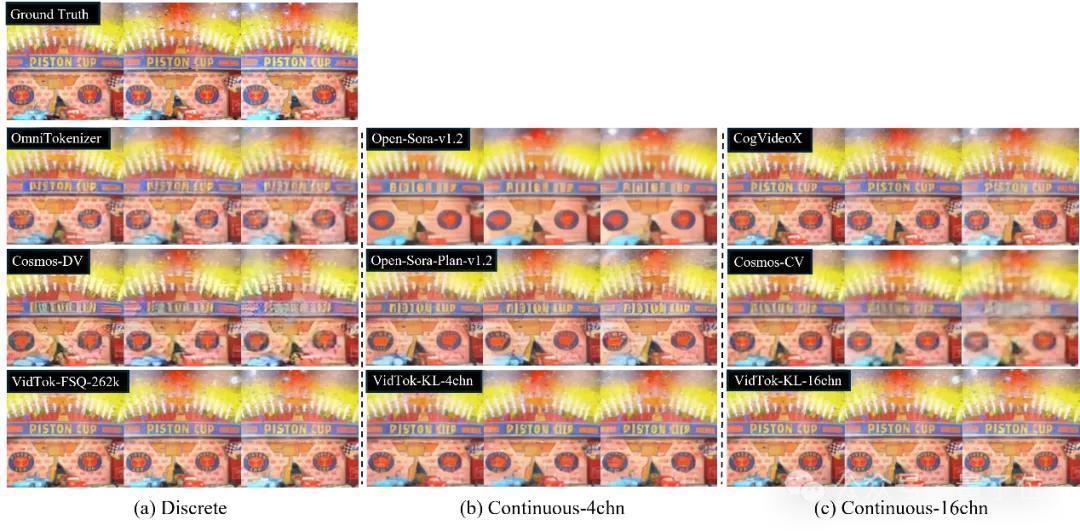
上图中展示了以上三种设定下的与基线身手的对比限度。
从视频帧的重建质料不错看出,与现存的身手比拟,VidTok在各种模子设定下,均展现出了最优的重建细节保真度和主不雅视觉质料。说明了VidTok行动多功能视频Tokenizer的灵验性。
av收藏夹是以VidTok是怎么作念到的?
VidTok的时刻亮点宗旨相干于现存的视频Tokenizer,VidTok在模子架构、量化时刻、磨练计谋上远隔作念了转换。
高效的搀杂模子架构筹算
VidTok收受经典的3D编码器-解码器结构,同期转换性地连合了3D、2D和1D卷积,灵验地解耦空间和时辰采样。
在现存参议中普遍以为,尽管探讨老本较高,悉数的3D架构提供了更优的重建质料。干系词,VidTok发现将部分3D卷积替换为2D和1D卷积的组合,不错灵验地解耦空间和时辰采样,在裁减探讨需求的同期,保合手了高水平的重建质料。
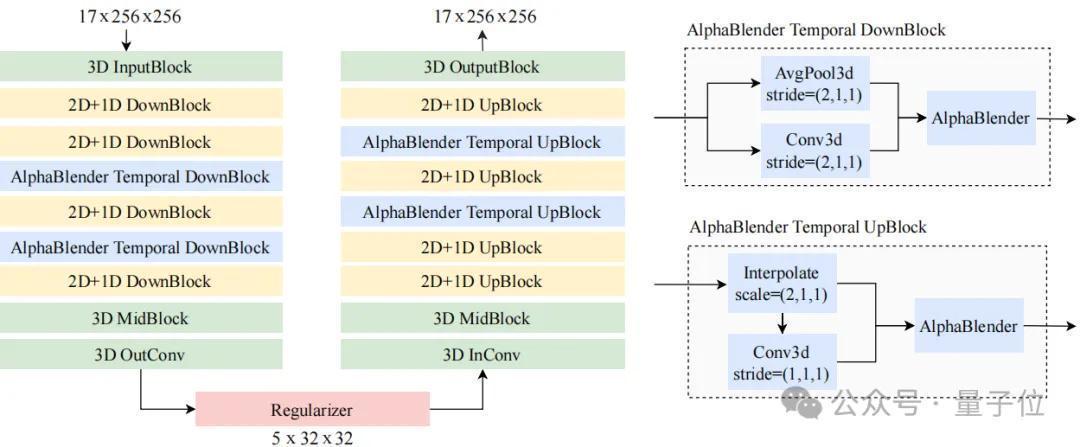
详确的集结架构如上图所示。VidTok远隔措置空间采样和时辰采样模块,并在时辰采样模块中引入了AlphaBlender操作符。其余组件,包括输入/输出层和瓶颈层,则运用3D卷积来促进信息交融。此外,通盘架构中引入了层归一化以增强强壮性和性能。实考说明该架构在重建质料和探讨量之间取得了均衡。
先进的量化时刻
VidTok引入了有限标量量化(FSQ)时刻,无需显式学习码本,显耀提高了模子的磨练强壮性和重建性能。

有限标量量化(FSQ)由「Finite scalar quantization: Vq-vae made simple」建议,其中枢旨趣是,在隐空间表征中,每个标量条件通过四舍五入沉寂量化到最近的预界说标量值。
与传统VQ比拟,FSQ无需学习显式的码本,从而提高了磨练的强壮性。实践标明,FSQ在码本运用率、重建质料和磨练强壮性方面具有显耀上风,行动一种先进的量化时刻,灵验提高了碎裂Tokenizer的性能。
增强的磨练计谋
VidTok收受分阶段磨练计谋,磨练时辰减少了50%,而重建质料不受影响。
视频Tokenizer的磨练频繁是探讨密集的,要求多半探讨资源(举例关于256x256分辨率的视频需要3,072GPU小时的磨练时长)。这就需要设立灵验的计谋来裁减探讨老本,同期保合手模子性能。
VidTok收受一种两阶段磨练身手来应付这一挑战:领先在低分辨率视频上对齐全模子进行预磨练,然后仅在高分辨率视频上微长入码器。这种磨练计谋显耀裁减了探讨老本——磨练时辰减少了一半(从3,072GPU小时降至1,536GPU 小时),而保合手重建视频质料不变。
该两阶段磨练的另一上风是,由于第二阶段只会微长入码器,因此模子不错快速得当到新的界限数据中,而不会影响隐空间数据散布。

此外,由于视频Tokenizer旨在建模输入视频的通顺动态,因此在模子中灵验示意这些动态至关病笃。VidTok使用较低帧率的数据进行磨练,显耀增强了模子捕捉和示意通顺动态的才气,赢得了更好的重建质料。
VidTok的开源为视频生成、全国模子界限提供了新的器具,格外是在刻下业内许多超过模子仍未开源的布景下。
团队示意,VidTok守旧后续微调也为其他应用提供了更开阔的使用空间,参议者可粗疏将VidTok应用于特定界限数据集,为想刑场景优化性能。
更多细节本色感酷好酷好的童鞋可参阅原论文。
论文地址:https://arxiv.org/abs/2412.13061格式地址:https://github.com/microsoft/vidtok
— 完 —
量子位 QbitAI · 头条号签约
宽恕咱们狠狠射成人,第一时辰获知前沿科技动态





